
AI Datasets: Powerful Strategies to Fake It Til You Make It (10/02)
Table of Contents
The quality and quantity of AI datasets are critical to training accurate and effective models. However, gathering real-world data can be expensive, time-consuming, or even impossible in some cases. This is where the phrase “fake it until you make it” can be applied to AI. By leveraging synthetic data, AI researchers can “fake” their way to success, allowing for robust model training even when real data is scarce.

Understanding the Role of AI Datasets
Before diving deeper into the strategies for working with synthetic data, it’s essential to understand the critical role that datasets play in the development of AI systems. Datasets are the foundation upon which AI models are built, as they provide the information needed for the model to learn, identify patterns, and make predictions. The importance of high-quality, diverse datasets cannot be overstated.

AI models, especially machine learning (ML) and deep learning (DL) models, rely on data to “learn” from past examples. The model processes the input data, learning relationships between different features (independent variables) and outcomes (dependent variables). The quality of these AI datasets directly influences how well the model can generalize to new, unseen data.
Training Data: This is the primary dataset used to teach the AI model. During training, the model analyzes patterns within the dataset to learn how to predict outcomes. If the training data is biased, incomplete, or unrepresentative, the model will inherit these flaws, leading to poor performance in real-world applications.
Validation Data: This dataset is used to evaluate the model during training to ensure it isn’t overfitting to the training data. It helps in adjusting the model’s parameters and determining how well the model generalizes to new data.
Test Data: After training is complete, the model is evaluated on a separate test dataset that it has never seen before. This ensures that the model’s performance in a controlled setting will translate to performance in the real world.

Challenges with Real-World Data
Despite the importance of datasets, real-world data can be challenging to work with. Some common issues include:
- Data Scarcity: In some domains, such as medical or financial fields, obtaining large amounts of real-world data is difficult due to privacy concerns, regulations, or costs.
- Imbalanced Datasets: In some cases, certain classes or outcomes may be underrepresented in the dataset. For instance, in fraud detection, the majority of transactions are legitimate, with only a small fraction representing fraudulent activity. Training on such an imbalanced dataset can lead to models that are biased toward predicting the majority class.
- Noisy or Incomplete Data: Real-world datasets often contain errors, missing values, or noise. Training on poor-quality data can lead to suboptimal models that make unreliable predictions.
- Data Privacy: Sensitive datasets, such as medical records or personal financial data, are often restricted, making it difficult for developers to access enough data for training.
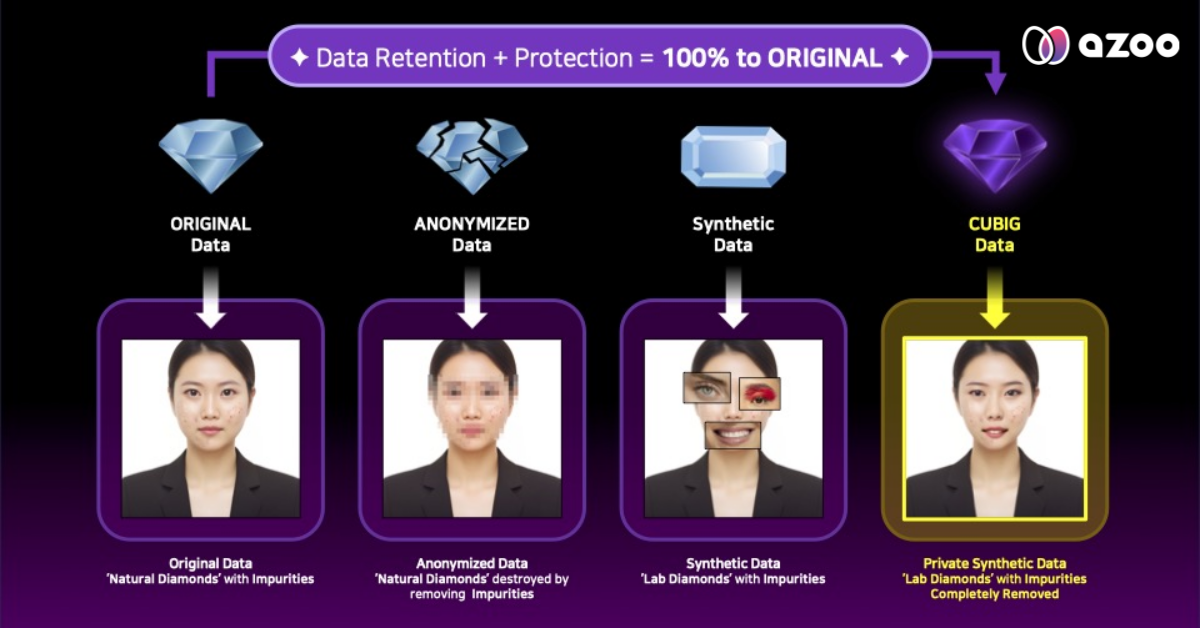
Fake AI Datasets with Generative AI
One of the most effective ways of faking AI datasets is through synthetic data generation using generative AI. Synthetic data refers to artificially generated data that simulates real-world characteristics. Generative AI, especially through techniques like Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Diffusion models (DMs) enables the creation of high-quality synthetic datasets that can closely mimic the properties of real data.
Advantages of Synthetic Data
One key advantage of synthetic data is that it allows for an unlimited amount of training data to be created. This can be particularly useful when training deep learning models that require large datasets to generalize effectively. Moreover, synthetic data can address the issue of data privacy, as the data generated doesn’t involve real individuals or sensitive information.