

An Incredible Way to Generate Synthetic Data Without Any Coding or Programming Knowledge (12/21)
1. General Knowledge
Many businesses hesitate to adopt synthetic data solutions due to concerns about the technical complexity and coding requirements involved. While synthetic data is a revolutionary technology that mirrors the statistical properties of real-world data while removing sensitive information, it is often perceived as too complicated for organizations without advanced technical teams.
Synthetic data allows businesses to bypass data privacy regulations such as GDPR and HIPAA, making it a key enabler for AI model training, data simulations, and advanced analytics. However, companies that fail to embrace this technology risk falling behind competitors who are already leveraging synthetic data to enhance innovation and drive data-driven decision-making.
Organizations that master synthetic data usage will likely dominate their industries by solving data privacy concerns and enabling the full utilization of their datasets. Yet, for many businesses—especially smaller ones—the perceived complexity acts as a barrier to entry, leaving them stuck in a cycle of data inaccessibility and unrealized potential.

2. Specific Challenges: Why Adopting Synthetic Data is Difficult
2.1. Lack of In-House Expertise in Small Businesses
Small and medium-sized businesses (SMBs) often face significant challenges due to their limited technical workforce and resources. Unlike large corporations that have dedicated data science teams and AI experts, SMBs may not have the budget or capacity to hire professionals who can manage complex data pipelines or implement advanced AI tools.
Traditional synthetic data solutions often require substantial technical expertise to get started. For instance, businesses need to:
- Set up data pipelines to clean, preprocess, and structure data.
- Integrate and configure synthetic data generation models.
- Continuously monitor and fine-tune these models for accuracy and performance.
For businesses without these in-house capabilities, even the initial steps toward adopting synthetic data can seem like an insurmountable barrier. This technical gap discourages many SMBs from exploring synthetic data solutions altogether, leaving them unable to compete with more technologically capable enterprises.
2.2. Dependency on External Synthetic Data Providers
Companies that lack the internal resources to create alternative datasets often seek support from external providers. However, this approach introduces an additional layer of complexity: the requirement for API integration.
Most platforms for generating data alternatives require businesses to:
- Connect their existing systems to external tools using APIs (Application Programming Interfaces).Understand basic coding principles to configure and customize these APIs effectively.Identify and resolve errors that may occur during the integration or operational process.
Without coding knowledge or technical expertise, many businesses find it nearly impossible to utilize these tools to their full potential. Even when external providers offer excellent solutions, businesses that cannot complete the integration process are left with an unusable product. As a result, these companies are effectively excluded from the benefits of synthetic data technology, despite their willingness to adopt it.
This reliance on external platforms, combined with the technical hurdles of integration, creates a significant barrier for businesses without strong technical foundations.
2.3. Security and Privacy Concerns
Security and privacy concerns are among the most common reasons businesses hesitate to adopt data generation solutions. Many organizations operate under the assumption that creating alternative datasets with external providers requires them to share their original data with third-party platforms. This perception raises several critical concerns:
- Data Privacy: Businesses worry that sharing sensitive information—such as customer records, medical data, or financial transactions—could result in privacy breaches or misuse. Industries like healthcare and finance, which are governed by strict regulations such as HIPAA and GDPR, are particularly cautious about exposing confidential data.
- Regulatory Violations: If data security is compromised during the creation process, organizations risk violating compliance standards, potentially facing legal penalties, lawsuits, and reputational damage.
- Financial Risks: A single data breach can lead to significant financial consequences, including fines, recovery costs, and loss of customer trust.
These concerns are especially heightened for organizations dealing with highly sensitive information. Without clear assurances that their data will remain protected, many businesses remain reluctant to explore privacy-preserving data solutions, regardless of their promising benefits.
2.4. Cost and Infrastructure Constraints
In addition to technical and security challenges, the cost of adopting data simulation solutions can be prohibitive for many organizations, particularly small and medium-sized businesses (SMBs). Traditional tools for generating alternative datasets often require:
- Investment in hardware infrastructure, such as high-performance servers or cloud-based storage solutions.
- Technical training to ensure employees can effectively operate, manage, and fine-tune the tools.
- Ongoing support to monitor, maintain, and update data systems as business requirements evolve.
For businesses operating with limited budgets, these financial commitments can make the adoption of data generation technologies seem impractical. Smaller organizations, in particular, may find it difficult to justify the expenses associated with building and sustaining the necessary infrastructure.
Moreover, many existing tools in this space are designed with large enterprises in mind—organizations that have ample technical expertise and financial resources. This dynamic further solidifies the perception that data generation technology is exclusive to well-funded corporations, leaving smaller players at a disadvantage.

3. CUBIG’s User-Friendly Synthetic Data Generation Solution
CUBIG has completely transformed the landscape of synthetic data generation by introducing an intuitive, user-friendly solution that eliminates the need for advanced coding skills or technical expertise. Businesses of all sizes, from small startups to large enterprises, can now generate high-quality synthetic data with ease. With CUBIG’s cutting-edge technology, the complex processes traditionally associated with synthetic data generation—such as programming, API integration, and data pipeline setup—are replaced by a simple, streamlined workflow that can be accomplished in just a few clicks.
CUBIG’s platform ensures that users, regardless of their technical background, can access the power of synthetic data without the challenges that come with traditional solutions. This opens new opportunities for businesses to innovate, leverage data-driven insights, and remain competitive in an increasingly digital and regulated environment.
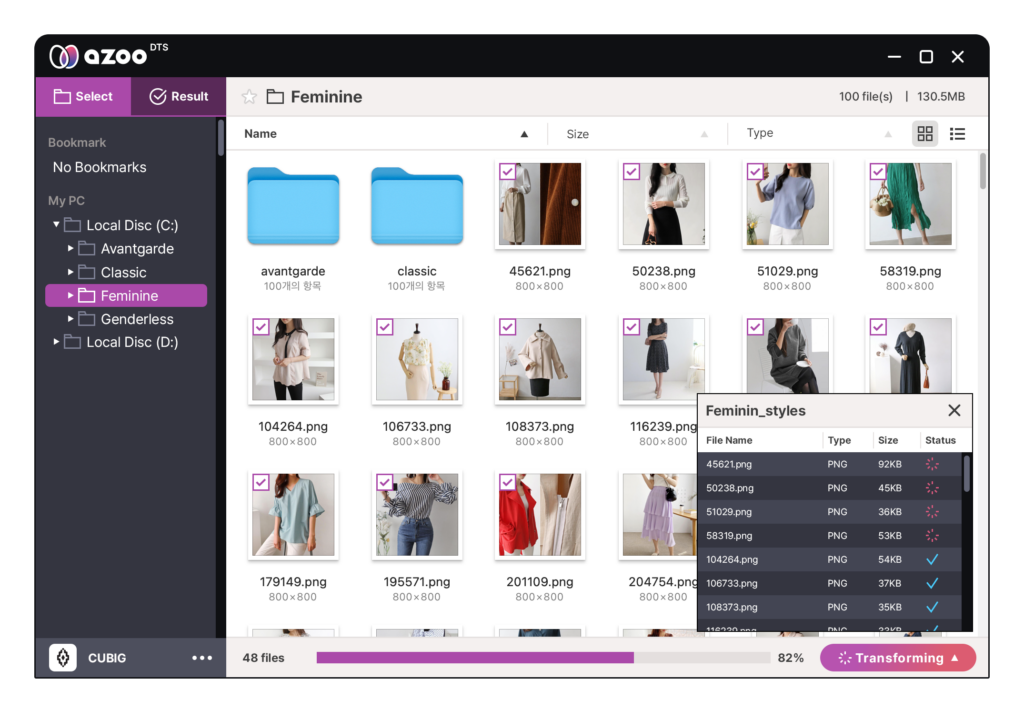
3.1. Simple Drag & Drop Method
At the heart of CUBIG’s simplicity is its Drag & Drop functionality, which makes synthetic data generation as intuitive as possible. Instead of requiring businesses to manually configure complex tools, write intricate code, or establish cumbersome API connections, CUBIG allows users to:
- Effortlessly upload their datasets: Users simply drag their original datasets onto CUBIG’s interface, a process familiar to anyone who has interacted with modern software tools.
- Automatically generate high-quality synthetic data: Once the data is uploaded, CUBIG’s platform takes care of the rest. The system processes the original dataset and produces synthetic data that retains its statistical properties, diversity, and utility—no coding required.
This intuitive workflow empowers non-technical users, such as small business owners, analysts, or general staff members, to:
- Generate realistic and high-performance synthetic data in minutes.
- Avoid reliance on in-house data scientists or external technical teams.
- Focus on utilizing the data to train AI models, perform analyses, and unlock actionable business insights.
For small and medium-sized businesses (SMBs) that lack the resources to invest in specialized AI talent, this feature is a game-changer. Even organizations with limited infrastructure or technical know-how can adopt synthetic data seamlessly, enabling them to innovate and compete with larger enterprises.
3.2. Addressing Security Concerns
One of the primary concerns businesses have when working with synthetic data is the risk of compromising the security and privacy of their original datasets. Traditional synthetic data platforms often require users to upload sensitive data to external servers, raising valid fears about data breaches, regulatory violations, and unauthorized access.
CUBIG, however, has been specifically designed to ensure that data privacy and security are never compromised. While the Drag & Drop method may give the impression of data being uploaded to an external platform, CUBIG employs sophisticated technologies to maintain complete data sovereignty for its users:
Differential Privacy Integration
CUBIG applies differential privacy throughout the synthetic data generation process. Differential privacy is a robust, mathematical framework that guarantees individual records in the original dataset cannot be inferred from the synthetic data. Even if an adversary attempts to reverse-engineer the generated data, differential privacy ensures that:
- The synthetic data remains secure and anonymized.
- No sensitive details or personally identifiable information (PII) can be extracted from the generated data.
This makes CUBIG’s synthetic data not only safe but also fully compliant with stringent data privacy regulations like GDPR (General Data Protection Regulation) in Europe and HIPAA (Health Insurance Portability and Accountability Act) in the United States.
Non-Access Technology
CUBIG takes privacy a step further with its non-access technology, which guarantees that the original data remains local to the user’s system. Despite the simplicity of the drag-and-drop interface, the platform processes the data without:
- Accessing the original dataset.
- Storing any part of the data on external servers.
Instead, CUBIG’s advanced algorithms analyze and generate synthetic data in a way that ensures:
- The original data remains completely secure and under the user’s full control.
- The resulting synthetic data achieves over 99% similarity to the original dataset in terms of statistical and analytical utility, making it a reliable substitute for real data in AI training, simulations, and research.
This level of privacy protection eliminates the risks typically associated with external platforms and assures businesses that they can use synthetic data safely without compromising the integrity of their original datasets.
3.3. Additional Benefits: Safe, Efficient, and Compliant
CUBIG’s solution is not only simple and secure but also comes with a range of additional benefits that further enhance its appeal:
- Enhanced Compliance: Businesses using CUBIG’s synthetic data remain fully compliant with data privacy regulations, including GDPR, HIPAA, and other industry-specific standards. By ensuring that no sensitive information can be extracted, CUBIG reduces regulatory risks and legal concerns.
- Increased Efficiency: Unlike traditional synthetic data tools that require significant time and effort to implement, CUBIG’s user-friendly platform allows businesses to generate synthetic data quickly and efficiently. This eliminates the need for costly infrastructure, technical training, or long setup processes.
- Resource Optimization: Businesses can now allocate their time and resources to data-driven innovation rather than struggling to overcome technical barriers. By simplifying synthetic data generation, CUBIG allows organizations to focus on tasks that directly impact growth, such as AI model development, customer insights, and operational improvements.
- Accessibility for All Businesses: CUBIG democratizes access to synthetic data, making it practical for businesses of all sizes. Small startups and enterprises alike can now harness the power of synthetic data without technical expertise, leveling the playing field in data-driven innovation.
4. Conclusion: Synthetic Data Made Accessible for All
CUBIG has redefined the way businesses approach synthetic data generation by eliminating technical barriers and delivering unmatched data security. Its intuitive drag-and-drop simplicity, combined with advanced privacy measures such as differential privacy and cutting-edge non-access technology, ensures that organizations can generate high-quality synthetic data safely and efficiently. This revolutionary approach makes synthetic data accessible to everyone—from small business owners and analysts to teams in large enterprises—without requiring any coding expertise or technical know-how. By simplifying the process and prioritizing security, CUBIG empowers businesses of all sizes to unlock the full potential of their data.
By addressing key challenges such as technical complexity, privacy concerns, and compliance issues, CUBIG enables businesses to:
- Unlock new opportunities through realistic, high-quality synthetic data.
- Innovate safely without compromising data security or regulatory compliance.
- Compete effectively in a data-driven world, regardless of their technical capabilities or size.
With CUBIG’s intuitive, user-friendly, and highly secure platform, synthetic data is no longer a privilege reserved for large corporations with extensive technical expertise and resources. It has now become an accessible and practical tool for businesses of all sizes, from small startups to global enterprises. CUBIG empowers organizations to seamlessly embrace the future of data innovation, enabling them to unlock valuable insights, drive AI advancements, and achieve their goals effortlessly, securely, and without technical barriers.
Discover how CUBIG can transform your data strategy and unlock the full potential of synthetic data—no coding required.
If you’d like to explore more about AI applications, synthetic data generation, and other insights, click here to check out our blog posts.